
Exploring Protein Structure
This Jmol Exploration was created using the Jmol Exploration Webpage Creator from the MSOE Center for BioMolecular Modeling.
1. Recognize/provide examples of how primary structure determines secondary structure (i.e, that it is hydrogen bonding between amino acids that determines formation of α helices and β sheets).
2. Recognize/provide examples of how primary and secondary structure influence tertiary structure (protein folding), which is important for creating functional domains.
3. Recognize/provide examples of how interactions between different proteins creates quaternary structures and that this is often necessary for protein function.
Your group will examine four proteins in this tutorial. Your TA will instruct you to view the proteins in a specific order. For each protein, please interact with the model. Click on the molecule and drag your mouse to spin the molecule. Scroll your mouse to zoom in and out. When you pause your mouse over a kink, a small pop up window will appear with a three-letter identifier for that amino acid (e.g., PRO for proline). Click practice protein below and briefly practice with the model.
Practice protein PDB ID: 1vkxThere is some important terminology to go over before you begin. Refer back to this section as needed throughout the tutorial as you learn about the different proteins (use the 'Content' bar on the top left of your screen to jump to different sections of this tutorial).
Backbone- this representation shows the peptide chain only, without the side chains (also called residues or R groups). Each kink on a chain represents the central α carbon of one amino acid. This is shown in grey in the model to the right.
Ball and stick- this representation is used to shows particular amino acid side chains. Each ball and stick color on a sidechain represents a different atom: white for hydrogen, black for carbon, blue for nitrogen, red for oxygen, yellow for sulfur. You do NOT have to memorize these colors, but note that the specific atoms that compose these side chains determine the properties of the amino acid (polar, nonpolar, negatively charged, etc.) and thus how the protein interacts with other biomolecules! Examples of ball and stick format are shown in the model to the right.
Hemoglobin is found in vertebrate red blood cells and is responsible for transporting oxygen from the lungs to the tissues of the body, and CO2 from the tissues to the lungs. Human hemoglobin is made up of four separate proteins or monomers (two α-globin and two β-globin) and each of these four proteins contains a ring-like heme group with an iron atom. Oxygen binds reversibly to these iron atoms, and so one hemoglobin can carry up to four oxygen molecules. Click on the button below to view hemoglobin.
hemoglobin structure PDB ID: 1a3nIn this model, hemoglobin is shown in a backbone format with important residues displayed in ball and stick format. α-globin molecules have a white backbone and β-globin molecules have a red backbone. Heme groups are shown here as essentially planar structures with an orange iron atom in the center. Move your mouse over one of the orange iron atoms and then keep the cursor there. A small pop up window with the 'HEM' label should appear.
You will now look at a single β-globin protein in more detail.
Based on their primary amino acid sequence, proteins adopt various secondary structures. Secondary structures include α helices and β sheets (β sheets are made of individual β strands). Hydrogen bonding between amino acids determines formation of α helices and β sheets. Click on the button below to view β-globin's secondary structure.
β-globin secondary structure PDB ID: 1a3nIn this model, backbone regions with α helices are colored red; backbones of β sheets are colored yellow. The grey shows regions that don't have secondary structure or regions that contain loops (another type of secondary structure that we'll talk about next week. The N (amino) terminus is blue and the C (carboxy) terminus is magenta. Locate the secondary structures of β-globin on your model(s).
Remember to interact with the protein by rotating it and zooming in and out.
Approximately how many α helices are found in a β-globin monomer?
Approximately how many β strands are found in a β-globin monomer?
Interactions between residues (R groups) determined by primary and secondary structure determine tertiary structure (protein folding) and allow for the formation of functional domains. In this case, proper folding allows amino acids (histidines) to properly align in each β-globin monomer in order to bind a heme group, which is able to bind an oxygen molecule. Click the button below to view the histidines thatcoordinate the heme group.
histidines that coordinate heme in β-globin PDB ID: 1a3nIn this image the heme group has an orange iron atom in the heme group center. Hold your cursor over one of the histidines that point towards the heme group. A yellow pop-up box will appear. The first three letters should be HIS (for histidine), followed by the residue #, the chain, the atom type and the atom number. Which two histidine residues coordinate (hold in place) the heme group?
Remember that in an aqueous environment, proteins tend to adopt tertiary structure and combine with other proteins (quaternary structure) so that hydrophilic residues tend to be on the __A__where they contact water, while hydrophobic residues tend to be on the __B__ of the protein, where they do not contact water.
A. inside; B. outside
A. inside B. inside
A. outside; B. outside
A. outside; B. inside
Click on the button below to locate the hydrophobic residues on β-globin.
β-globin hydrophobic residues PDB ID: 1a3nIn this model, β-globin is displayed as a backbone structure with hydrophobic residues displayed in ball and stick and colored yellow.
In the case of β-globin, the folding of the protein into its tertiary structure does not result in the hydrophobic residues on the inside. This is because β-globin is just one subunit (monomer) of a larger protein complex. In order to function, some proteins must adopt quaternary structure, which requires the association of two or more proteins. Quaternary structure is largely driven by the need to bury hydrophobic regions from contact with the cytoplasm. To bury the hydrophobic region on the α- and β-globin monomers, four monomers come together at these regions. Forming the entire hemoglobin molecule is favorable because burying these large hydrophobic regions in the interior contact surfaces of each monomer creates a highly stable protein.
Click on the button below to see the quaternary structure of hemoglobin.
This model is again displayed as a backbone structure, but now hydrophobic residues are displayed in ball and stick and colored yellow.
Although each globin monomer can independently bind an oxygen molecule, the quaternary structure of hemoglobin allows for more efficient oxygen binding. This is because the binding of an oxygen to one globin subunit causes conformational changes in the whole protein complex. These conformational changes make it easier for oxygen to bind the heme groups of the remaining subunits.
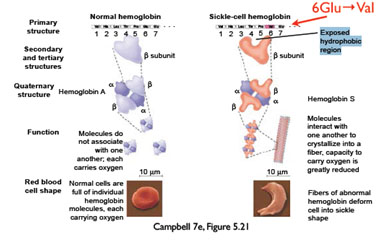
Primary structure ultimately determines how a protein folds into a functional unit. Often, changing a single amino acid results in dramatic changes in protein folding and thus protein function. For example, replacing β-globin's polar amino acid glutamate (at the 6th amino acid position) with a nonpolar valine, which can occur due to a single DNA base pair mutation, changes the shape of the protein and results in sickle cell anemia.
Click on the button below to see a hemoglobin molecule with two β-globin proteins shown in red. The green residues represent the position of the two glutamate residue 6's (shown as GLU6 in the pop up window when you pause your mouse over a green residue). These two glutamate residues are mutated to valines in people with sickle cell anemia.
The nonpolar valine is hydrophobic, and makes the hemoglobin molecule stick to another hemoglobin molecule in order to shield this region from the watery environment. This results in the formation of long fibers that cannot carry as much oxygen, and which also distort the shape of the red blood cells.
Do you think that hemoglobin function would change if the glutamate was replaced with another polar amino acid? Briefly explain.
Green fluorescent protein (GFP) is found in a jellyfish (Aequorea victoria) that lives in the North Pacific Ocean. The jellyfish also contains a bioluminescent protein, aequorin, which emits blue light. GFP absorbs this blue light and emits green light, which is what we actually see when the jellyfish lights up. Solutions of purified GFP glow bright green when exposed to blue light. Click on the button below to see a model of GFP.
GFP PDB ID: 1embIn this model, GFP is shown in a backbone format with important residues displayed in ball and stick.
Based on their primary amino acid sequence, proteins adopt various secondary structures. Secondary structures include α helices and β sheets (β sheets are made of individual β strands). Click on the button below to view GFP's secondary structure.
GFP secondary structure PDB ID: 1embIn this model, backbone regions with α helices are colored red; backbones of β sheets are colored yellow. The grey shows regions that don't have secondary structure or regions that contain loops (another type of secondary structure that we'll talk about next week. The amino (N) terminus is blue and the carboxyl (C) terminus is magenta. Locate the secondary structures of GFP on your model(s).
Remember to interact with the protein by rotating it and zooming in and out.
Approximately how many α helices are there in GFP?
Approximately how many β strands are there in GFP?
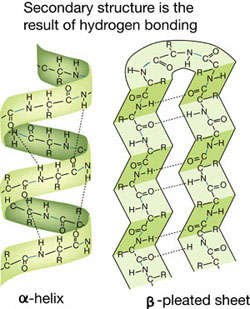
Hydrogen bonding between amino acids determines formation of α helices and β sheets. Click on the button below to see hydrogen bonds displayed in white within the secondary structures.
GFP secondary structure with hydrogen bonds PDB ID: 1embNote that in α helices, each hydrogen bond is between the amino (N-H) group of one amino acid and the carbonyl (C=O) group of a second amino acid, separated linearly along the protein chain by four amino acids (see figure below). In β sheets the hydrogen bonds are between different segments of the protein (but still between the amino (N-H) group of one amino acid and the carbonyl (C=O) group of a second amino acid).
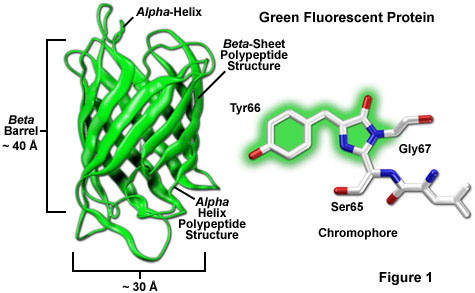
Interactions between residues (R groups) determined by primary and secondary structure determine tertiary structure (protein folding) and allow for the formation of functional domains. In the case of GFP, the proper folding forms a β barrel or can with a single strand of amino acids though the center (Yang et al 1996). A three amino acid sequence: serine, tyrosine, and glycine (sometimes the serine is replaced by the similar threonine) is buried inside the β barrel, protected from the watery environment. The following image shows these three amino acids as ball and stick inside the β barrel.
3 key amino acids of GFP PDB ID: 1embThese three amino acids are positioned in such a way that they undergo a series of chemical reactions that result in a fluorescent chromophore (region where light can be absorbed and emitted in a visible wavelength). The fluorescence could not occur if these amino acids were exposed to the surrounding environment.
Remember that in an aqueous environment, proteins tend to adopt tertiary structure and combine with other proteins (quaternary structure) so that hydrophilic residues tend to be on the _A_ of the protein, where they contact water, while hydrophobic residues tend to be on the _B_ of the protein, where they do not contact water.
A. inside; B. outside
A. inside; B. inside
A. outside; B. outside
A. outside; B. inside
Click on the buttons below to see two different models showing the hydrophobic residues highlighted in yellow. The backbone model shows hydrophobic residues in ball and stick on the backbone. The 'slab feature' shows the cross section of GFP in spacefill format. Left click and drag your mouse to rotate the image and see different cross sections.
hydrophobic amino acids - backbone PDB ID: 1embWhere are the hydrophobic amino acids in GFP located?
All are on the inside of the β barrel
Most are on the inside of the β barrel
All are on the outside of the β barrel
Most are on the outside of the β barrel
GFP has no quaternary structure, as a single protein chain folds to become a functional protein.
A main function of Cdc42 Interacting Protein 4 (CIP4) is to help create elongated, tubular vesicles during endocytosis. You will learn more about CIP4 in the third unit of this semester.
CIP4 is a homodimeric protein (meaning it forms a dimer composed of two identical subunits) with three major domains: F-BAR, SH3, and HR1. You can see one CIP4 subunit (also called a 'monomer') with its three domains in the figure below.
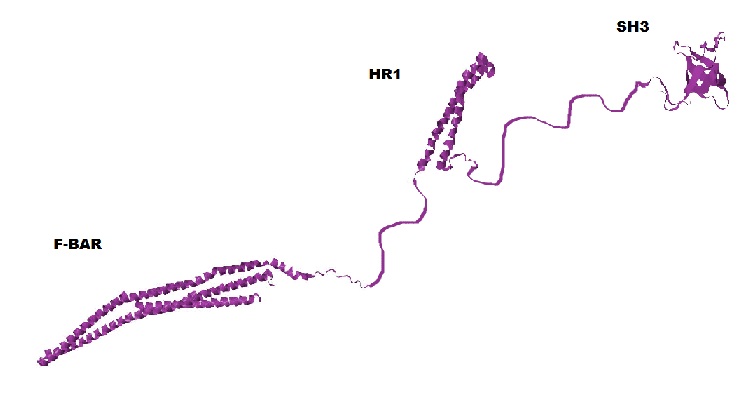
Based on their primary amino acid sequence, proteins adopt various secondary structures. Secondary structures include α helices and β sheets (β sheets are made of individual β strands). The F-BAR and HR1 domains are primarily α helices and the SH3 domain consists of primarily β sheets. (Shimada et al 2007, Kobashigawa et al 2009, Miyamoto et al unpublished). However, a large amount of CIP4's secondary structure is unknown, because it is unable to be determined with the technology currently available. In the above figure these unknown regions are shown as thin strings connecting the F-BAR, HR1 and SH3 domains.
The rest of this section will focus on the F-BAR domain. Click on the button below to view the secondary structure of the F-BAR domain.
In this model, backbone regions with α helices are colored red; backbones of β sheets are colored yellow. Regions that do not have a secondary structure are grey. The N (amino) terminus is blue and the C (carboxyl) terminus of the F-BAR domain is magenta (note that the C terminus of the CIP4 protein is part of the SH3 domain). Locate the secondary structures of the F-BAR domain on your model(s).
Approximately how many α helices are there in the FBAR domain of CIP4?
Approximately how many β strands are there in the F-BAR domain of CIP4?
Hydrogen bonding between amino acids determines formation of α helices and β sheets. Click on the button below to see hydrogen bonds displayed in white within the secondary structures.
F-BAR domain secondary structure with hydrogen bonds PDB ID: 2efkNote that in α helices, each hydrogen bond is between the amino (N-H) group of one amino acid and the carbonyl (C=O) group of a second amino acid, separated linearly along the protein chain by four amino acids (see figure below). In β sheets the hydrogen bonds are between different segments of the protein (but still between the amino (N-H) group of one amino acid and the carbonyl (C=O) group of a second amino acid).

Interactions between residues (R groups) determined by primary and secondary structure determine tertiary structure (protein folding) and allow for the formation of functional domains. The functional domains of CIP4 are discussed below.
The tertiary structure of CIP4 forms α helical bundles and a β barrel. The three long α helices of the F-BAR functional domain form an α helical bundle, the α helices of HR1 form an α helical bundle, and the SH3 domain's β sheets form a single β barrel.
Remember that in an aqueous environment, proteins tend to adopt tertiary structure and combine with other proteins (quaternary structure) so that hydrophilic residues tend to be on the _A_ of the protein, where they contact water, while hydrophobic residues tend to be on the _B_ of the protein, where they do not contact water.
A. inside; B. outside
A. inside; B. inside
A. outside; B. outside
A. outside; B. inside
We will just focus on the F-BAR domain of one CIP4 subunit for the next sections. Click on the button below to locate the hydrophobic residues on an F-BAR domain.
F-BAR monomer hydrophobic residues PDB ID: 2efkIn this model the F-BAR domain is displayed as a backbone structure with hydrophobic residues displayed in ball and stick and colored yellow. Remember to interact with the protein by rotating it and zooming in and out.
In the case of CIP4, the folding of the protein into its tertiary structure does not result in the hydrophobic residues on the inside. This is because a single CIP4 protein (monomer) must bind with another monomer to be functional.
In order to function, some proteins must adopt quaternary structure, which is the interaction of two or more proteins. The formation of quaternary structure is largely driven by the need to bury hydrophobic regions from contact with the cytoplasm. To bury the hydrophobic region of the F-BAR domain on the monomer, two monomers come together at these regions to form a dimer. Forming the dimer is favorable because burying these large hydrophobic regions in the interior dimer contact surface creates a highly stable protein (Masuda and Mochizuki 2010). The portion of the F-BAR domain of one CIP4 protein that contacts the F-BAR domain of another CIP4 molecule to form a dimer contains three α helical bundles which are rich in hydrophobic amino acids, while the outer side is rich in hydrophilic amino acids. This causes the F-BAR domain to adapt a banana-shaped structure. Click the button below to see the F-BAR dimer.
F-BAR dimer hydrophobic region PDB ID: 2efk (biological assembly)The proper folding of the F-BAR domain (tertiary structure) and dimerization (quaternary structure) results in the alignment of positively changed amino acids on the concave side of the dimer. This will be important as you learn more about CIP4 function later in the semester. Click on the button below to see the F-BAR domain of one CIP4 monomer displayed as a backbone structure with positively charged residues displayed in ball and stick and colored blue.
positively charged residues in F-BAR dimerCIP4 is a relatively large protein. The F-BAR domain alone is 22 nm long. Compare this to a compact protein like GFP, which is 3 x 4 nm. Revisit the site you used for the activity last weekend for more information on scale http://learn.genetics.utah.edu/content/cells/scale/.
How does the size of hemoglobin compare to the size of the F-BAR domain and GFP? (see http://learn.genetics.utah.edu/content/cells/scale/)
Hemoglobin is larger than both
Hemoglobin is smaller than both
Hemoglobin is larger than F-BAR but smaller than GFP
Hemoglobin is larger than GFP but smaller than F-BAR
Proteins that bind DNA and are involved in transcribing RNA from DNA are called transcription factors. Nuclear Factor-kappaB (NF-ĸB) proteins make up a family of eukaryotic transcription factors that are involved in the control of many cellular processes, such as immune and inflammatory responses, developmental processes, cellular growth, and apoptosis. NF-ĸBs are also persistently active in a number of disease states, including HIV infection, cancer, arthritis, chronic inflammation, asthma, neurodegenerative diseases, and heart disease. NF-ĸB is made up of two protein chains (one p50 subunit and one p65 subunit). NF-ĸB is therefore called a heterodimer because it is composed of two different subunits. Click the button below to see the p65 subunit of NF-ĸB.
p65 protein of NF-ĸB PDB ID: 1vkxIn this model, the p65 protein of NF-ĸB is shown in a backbone format. The DNA binding domain is shown in blue and the dimerization domain is shown in purple. You will learn more about each of these domains. The grey amino acids represent a 'linker' region between the DNA binding domain and the dimerization domain.
Based on their primary amino acid sequence, proteins adopt various secondary structures. Secondary structures include α helices and β sheets (β sheets are made of individual β strands). Click on the button below to view secondary structure of the p65 subunit of NF-ĸB.
p65 secondary structure PDB ID: 1vkxIn this model, backbone regions with α helices are colored red; backbones of β sheets are colored yellow. The grey shows regions that don't have secondary structure or regions that contain loops (another type of secondary structure that we'll talk about next week. Note that p65 contains many loops. The N (amino) terminus is blue and the C (carboxyl) terminus is magenta. Locate the secondary structure on the p65 protein.
Remember to interact with the protein by rotating it and zooming in and out.
Approximately how many α helices are there?
Approximately how many β strands are there?
Hydrogen bonding between amino acids determines formation of α helices and β sheets. Click on the button below to see hydrogen bonds displayed in white within the secondary structures.
p65 secondary structure with hydrogen bonds PDB ID: 1vkxNote that in α helices, each hydrogen bond is between the amino (N-H) group of one amino acid and the carbonyl (C=O) group of a second amino acid, separated linearly along the protein chain by four amino acids (see figure below). In β sheets the hydrogen bonds are between different segments of the protein (but still between the amino (N-H) group of one amino acid and the carbonyl (C=O) group of a second amino acid).
Interactions between residues (R groups) determined by primary and secondary structure determine tertiary structure (protein folding) and allow for the formation of functional domains. In this case, DNA binding domains (regions that interact with DNA). Click on the button below to see the DNA binding domain of one p65 subunit of NF-ĸB.
p65 DNA binding residues PDB ID: 1vkxThe DNA binding domain is shown in blue. Four of the amino acids in the p65 protein that bind DNA are shown. These are primarily positively charged amino acids that interact with the negatively charged DNA.
Remember that in an aqueous environment, proteins tend to adopt tertiary structure and combine with other proteins (quaternary structure) so that hydrophilic residues tend to be on the _A_ of the protein, where they contact water, while hydrophobic residues tend to be on the _B_ of the protein, where they do not contact water.
A. inside; B. outside
A. inside; B. inside
A. outside; B. outside
A. outside; B. inside
Click on the button below to locate the hydrophobic residues on the p65 subunit of NF-kB. In this model, p65 is displayed as a backbone structure with hydrophobic residues displayed in ball and stick and colored yellow.
p65 hydrophobic regions PDB ID: 1vkxAs stated above, NF-κB is a heterodimer, meaning it is composed of two distinct monomers or subunits (the p50 and p65 subunits). Residues from each subunit bind via hydrogen bonds and van der Waals interactions (Huxford et al 1998). Click on the button below to see the quaternary structure of NF-κB.
NF-kB dimer PDB ID: 1vkxIn this model, the p65 monomer backbone is in dark colors and the p50 monomer is in light colors. The amino acids that interact in dimer formation are displayed in ball and stick.
You saw the amimo acids in the p65 protein that bind DNA above, but quaternary structure (that is, both the p65 and p50 proteins) must be present for NF-ĸB to be functional. The following model shows the amino acids that bind DNA in both the p65 and p50 proteins. You will see DNA (white) appear after a few seconds. Notice how nicely DNA fits into the space between the protein chains. The second button shows the protein without the DNA bound.
Name one amino acid from each protein that interacts with DNA. Specify the protein chain for each. (To identify amino acids, follow these instructions: Hold your cursor over one of the amino acids. A yellow pop-up box will appear. The first three letters refer to the amino acid (e.g. HIS or PRO), followed by the residue #, the chain, the atom type and the atom number).
Chen FE, Huang D, Chen Y, and Gosh G (1998) Crystal structure of p50/p65 heterodimer of transcription factor NF-kB bound to DNA. Nature 391: 410-413
Huxford T, Huang DB, Malek S, Ghosh G (1998) The crystal structure of the ikappabalpha/nf-kappab complex reveals mechanisms of nf-kappab inactivation. Cell. 95(6):759
Jacobs MD and Harrison SC (1998). Structure of an IκBα/NF-κB Complex. Cell. 95(6):749–758
Kobashigawa Y, Kumeta H, Kanoh D, Inagaki F (2009). The NMR structure of the TC10- and Cdc42-interacting domain of CIP4. Journal of Biomolecular NMR 44: 113-118
Masuda M and Mochizuki N (2010). Structural characteristics of BAR domain superfamily to sculpt the membrane. Semin Cell Dev Biol. 21(4):391-8
Miyamoto K, Tomizawa T, Koshiba S, Inoue M, Kigawa T, Yokoyama S (Unpublished). Solution strutcure of the sh3 domain of the cdc42-interacting protein 4.
Perutz M.F. (1978): Hemoglobin Structure and Respiratory Transport. Scientific American, 239 (6).
Shimada A, Niwa H, Tsujita K, Suetsugu S, Nitta K, Hanawa-Suetsugu K, Akasaka R, Nishino Y, Toyama M, Chen L, Liu ZJ, Wang BC, Yamamoto M, Terada T, Miyazawa A, Tanaka A, Sugano S, Shirouzu M, Nagayama K, Takenawa T, Yokoyama S (2007). Curved EFC/F-BAR-domain dimers are joined end to end into a filament for membrane invagination in endocytosis. Cell 129: 761-772
Yang F, Moss LG, Phillips GN Jr (1996). The molecular structure of green fluorescent protein. Nat Biotechnol. 14(10):1246-51.
Save/Export Your Answers to the Questions in This Jmol Exploration